 Talk to an Expert
855-FOR-SKAI
Talk to an Expert
855-FOR-SKAI
At SKAIVISION, we are committed to bringing AI into automotive dealerships using their existing cameras to enable them to be proactive.
One part of that is utilizing customer and employee poses information to provide more context within a scene. To determine the pose of the individual, a pose model that provides key points is used in combination with distance and angle calculations, as well as a classical machine learning model. Distances are normalized by the length of the shoulder-to-waistline segment to prevent the model from being trained on the distance from the camera.
At present, we have support built for the following gestures: fall, firearm, semaphore flags, and sitting. The semaphore flags are shown in the image below (source: Britannica); however, we do not require physical flags and are instead examining wrist and elbow placements from a various of camera angles.
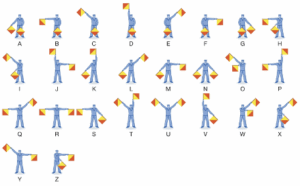
These poses allow us to focus on safety (fall), security (firearm), customer/employee idle (sitting), and service (semaphore flags). The semaphore flags are used for service, allowing a technician to have the system help determine what is needed (e.g., semaphore A for an air filter delivery) rather than having the technician stop work to enter data into a computer.
A large number of machine learning models were examined over different versions of YOLO. A subsample of the results are provided below:

As expected, YOLO 11 consistently outperforms YOLO 8, particularly in firearm detection, and the larger models demonstrate greater efficacy at the expense of compute speed and GPU memory.
The approach we took is data-driven. A significant number of images are used for the different gestures, and the model determines, based on distance and angle calculations, which gesture it is likely seeing. This was done so that as issues are seen where the model is not working (due to camera angle/lighting/occlusion/…), more data (positive and negative) can be collected and put into the appropriate folders for training. The model can then be automatically retrained to handle those scenarios.
In the future, we will add more poses (holding a tablet, on the phone, …) that can be used as metadata for other events, such as customer vs. employee.
Interest in learning more? Sign up for our newsletter.

